

月之暗面发布 Kimi K2.6:开源编程模型的突破性进展
月之暗面昨晚发布了 Kimi K2.6,依旧保持开源。然而,此次发布的亮点远不止于此。Kimi K2.6 的编程能力不仅达到了开源领域的 SOTA(最先进技术),而且在性能上甚至超越了两个闭源模型。
在 SWE-Bench Pro 58.6 的基准测试中,Kimi K2.6 的成绩超过了 GPT-5.4(xhigh)和 Claude Opus 4.6(max effort)。这意味着,一个开源模型首次在主流基准上取得了对几乎最强两个闭源模型的压制优势。
跑分只是故事的一半
我们知道,跑分高是一回事,但能否在真实场景中长时间、高强度地工作则是另一回事。Kimi K2.6 显然也深知这一点,因此其在这一方面的进步可能比跑分更值得关注。K2.6 可以连续工作 12 小时而不崩盘。
官方提供的案例之一是:在 Mac 上使用 Zig 语言本地部署 Qwen3.5-0.8B 模型,整个过程涉及 4000 多次工具调用,跨越 14 轮迭代,持续了 12 个小时。最终,它以 193 tokens/sec 的推理速度完成了任务,比 LM Studio 快了 20%。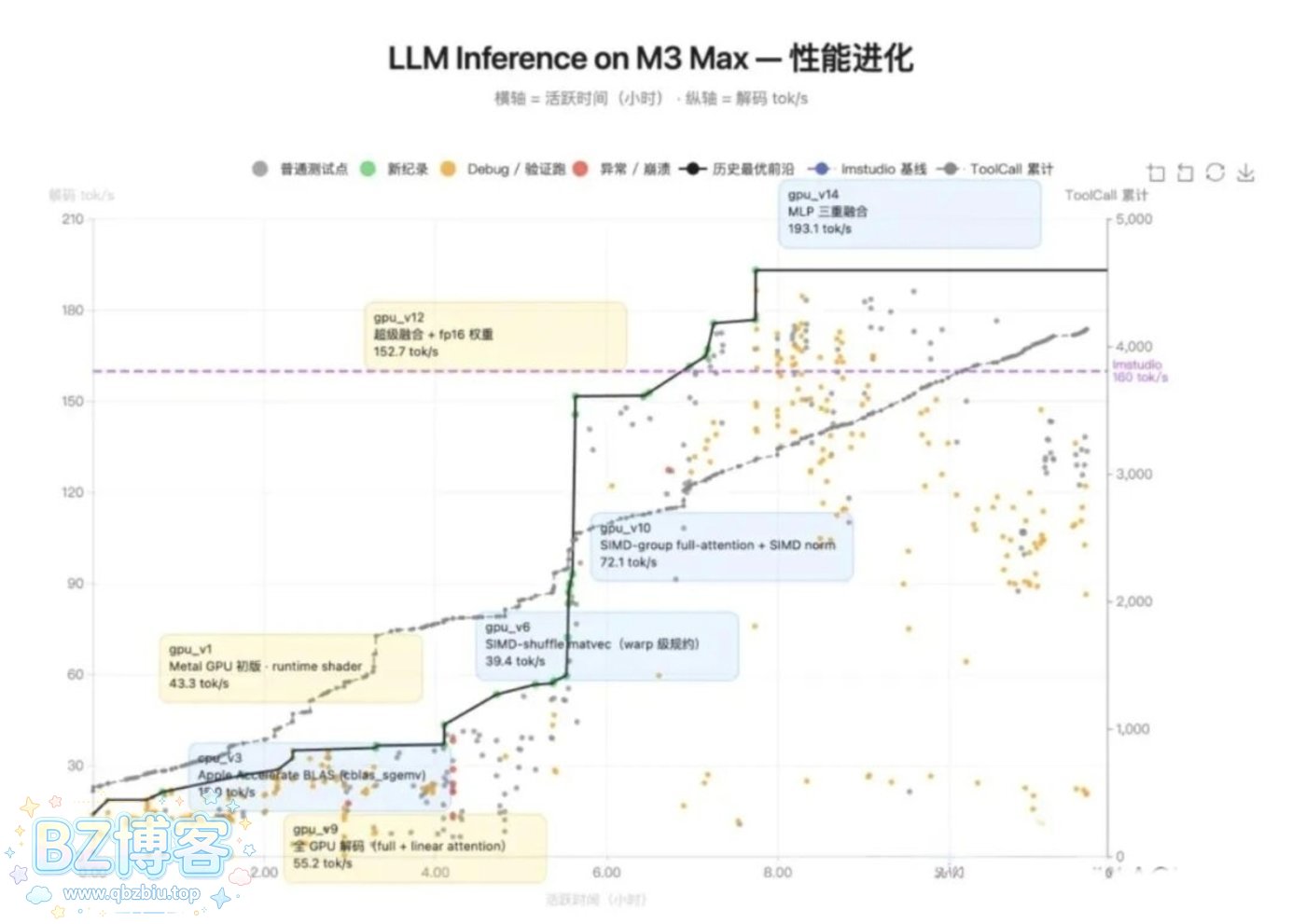
另一个硬核案例是对 exchange-core 金融撮合引擎进行全面重构,13 个小时,1000 多次工具调用,修改了 4000 多行代码。中等负载吞吐量提升了 185%,整体性能提升了 133%。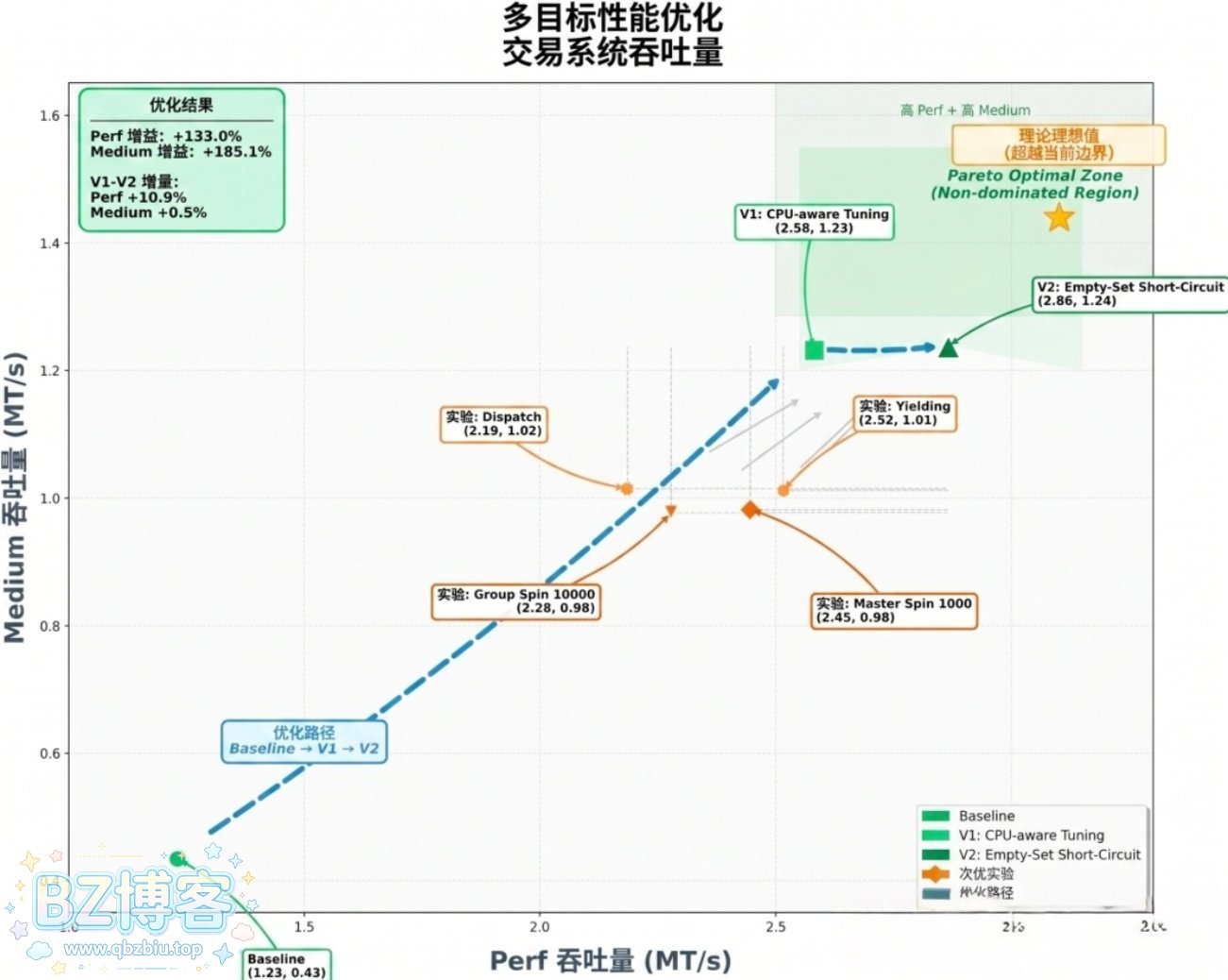
多语言和框架的泛化能力
换句话说,K2.6 已经能像一个靠谱的工程师那样,连续干十几个小时的活,中间不掉链子。而且,它根本就不挑语言。Rust、Go、Python、前端、DevOps 工作流,都能稳定输出。官方的说法是:“跨语言和框架的泛化能力。”
Vercel 表示 K2.6 在 Next.js 基准上的表现提升了超过 50%。CodeBuddy 报告了 18% 的长上下文稳定性提升和 96.60% 的工具调用成功率。
此外,K2.6 的平均步骤数比 K2.5 减少了约 35%。更少的步骤意味着更少的 token 消耗,更少的出错机会,和更快的速度。用更短的路径走到正确答案,这其实是模型“聪明”程度的一个更加直观的衡量方式。
内部的 Kimi Code Bench 基准测试成绩也佐证了这一点:K2.6 从 K2.5 的 57.4 提升到了 68.2,直接涨了将近 20%。
300 个 Agent 上岗
然后,就是这次的重头戏了。K2.6 的 Agent 集群功能,虽然从 K2.5 就开始引入,但我的感受是,这次才算是真正的成熟了。
我们只需要给它一个任务,它会自动拆解,创建一堆不同角色的“分身”,让它们并行工作。K2.5 的上限是 100 个子 Agent、1500 步,而到了 K2.6 这里,则直接拉到了 300 个子 Agent、4000 步。一个人,一句指令,一支团队。我当然,得亲自来试一试。
相关链接
- Kimi 官网:https://kimi.com
- Kimi Code:https://kimi.com/code









请登录后发表评论
注册
社交账号登录
停留在世界边缘,与之惜别